
CLIPのエンコード機能の活用に関する調査
CLIP(Contrastive Language-Image Pretraining)は、OpenAIによって開発された人工知能モデルです。画像とそれに関連するテキストを一緒に学習させることで、画像とテキストのペアをそれぞれの意味を保持して関連付けることが出来ます。これにより、画像とテキストの間で意味の類似性を計算したり、テキストと同じ意味を持つ画像を検索することが出来ます。またCLIPはゼロショット学習能力を持ち、事前に訓練されていない特定のタスクに対しても、一般的な知識に基づいて予測を行うことができます。
図1)CLIPの事前学習およびゼロショット推論の処理イメージ
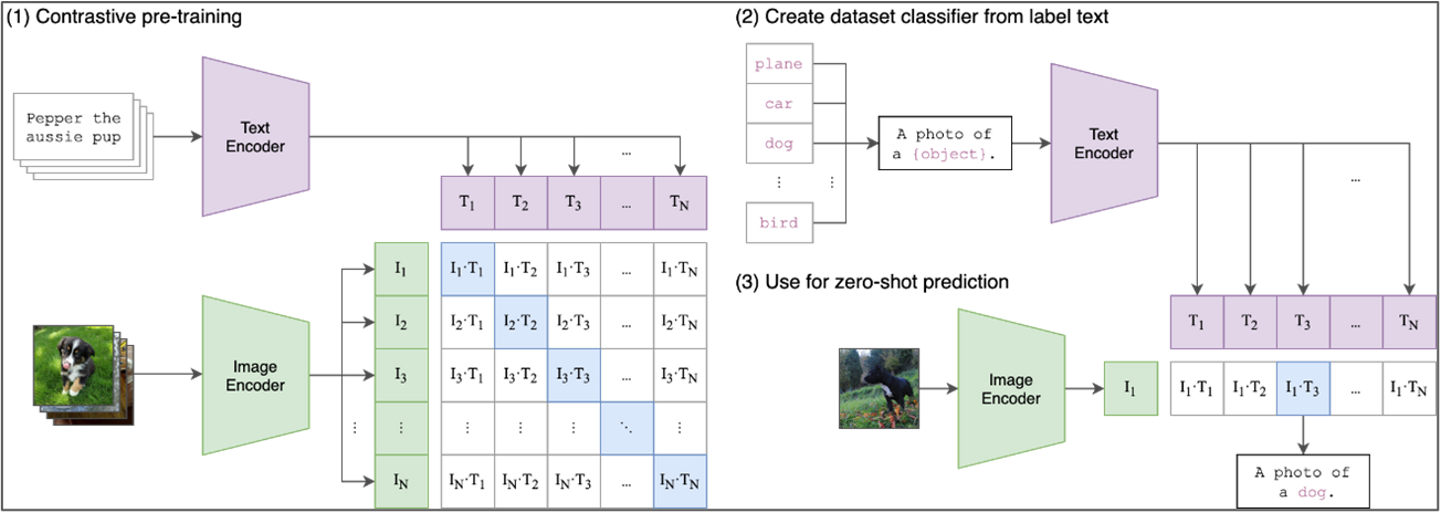
※引用:GitHubサイト(openai/CLIP)より
弊社では、このCLIPについてテキスト検索による画像抽出テストを検証してみました。テストの内容としては、テキスト(英文)にて「歌っている」という検索条件を設定し、弊社が保有する200枚の宴会画像の中から、テキストに該当する画像を抽出するというものです。結果は80%の精度で、条件に合った画像を抽出することに成功しました。
図2)テキスト条件による画像検索
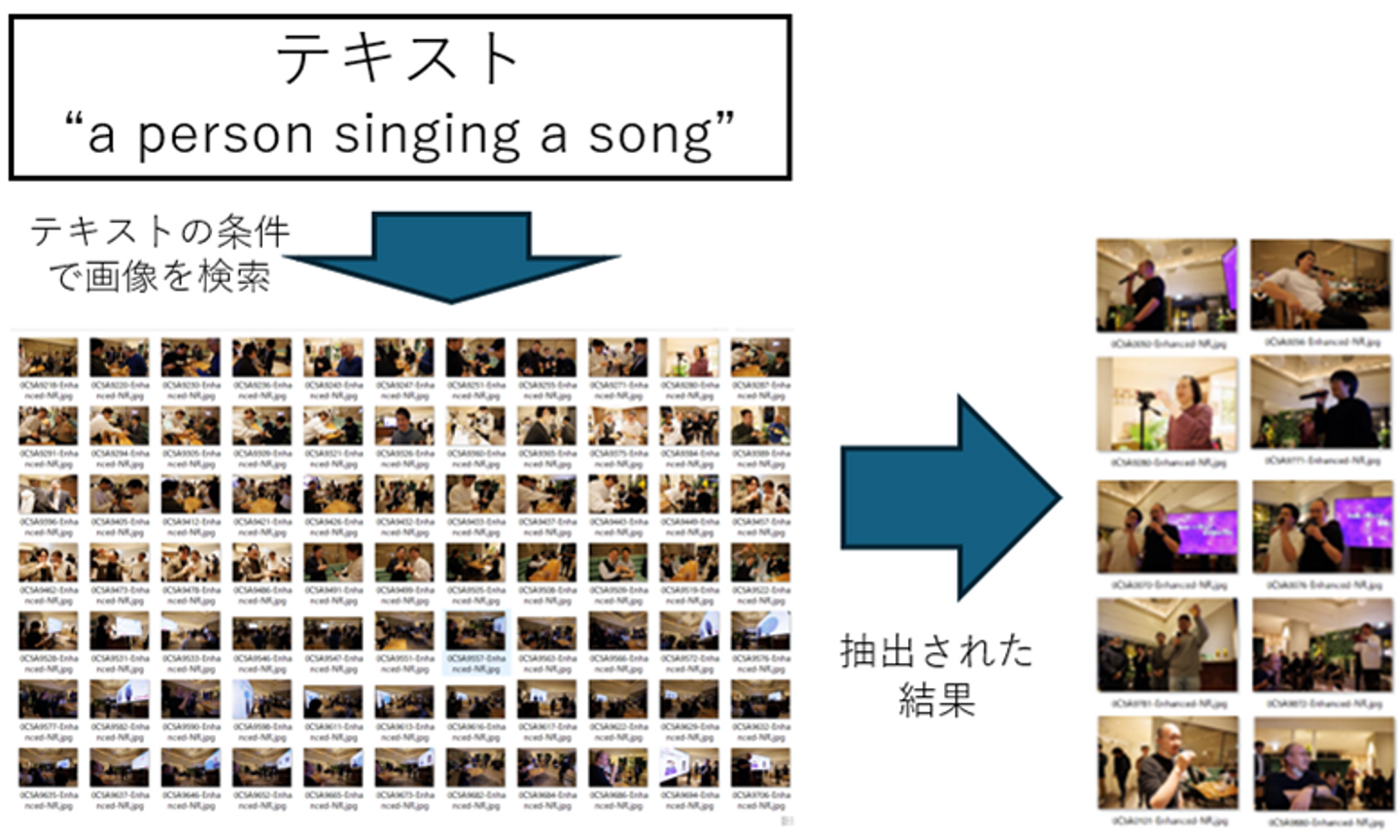
CLIPの特性においては、1枚の画像に複数の情報が含まれていることから、入力するテキストの意味に完全に合致する情報が画像内で埋もれてしまう場合があることも確認されています。このため、特定の検索条件に対して、画像から適切な情報を抽出できないケースも存在します。
また、テキストの書き方や表現方法が検索結果に大きく影響するため、入力するテキストの工夫も重要です。これらの特性を理解し、活用することで、より正確で有用な画像検索結果を得るための最適化が可能になります。
弊社では、このようなCLIPの特性を踏まえ、お客様が抱える課題を解決するための更なるリサーチと技術改善を進めています。今後も精度向上に向けた取り組みを強化し、より効率的な画像検索システムの提供を目指してまいります。
株式会社アプリズムでは、
若手のAIエンジニアを募集しております!
是非ともご応募くださいませ!
/assets/images/20843064/original/c09be86e-3e7e-43d2-9e08-2ed1f1657325?1745540291)

/assets/images/1555769/original/bab1cc11-ae51-4670-92ec-a0fc8866946a.png?1491532325)
/assets/images/1555769/original/bab1cc11-ae51-4670-92ec-a0fc8866946a.png?1491532325)


