Agent architecture and decision loops

Agents and Agentic AI is what everyone is talking about nowadays. While the concept is powerful, the difficulties developers face when developing such systems are more challenging compared to regular LLM applications. Unlike a simple chain of prompts or fixed pipelines, an LLM-based agent can dynamically decide what actions to take, which tools to use, and when to stop, all by leveraging the reasoning capabilities of a (LLM). In this session we will explore what agent architectures look like, how they operate through decision loops, and how new frameworks like LangGraph can help implement these agents more robustly.
Defining an AI Agent
In simple terms, an AI agent is a system that uses an LLM to decide the control flow of an application. Traditional LLM applications often have a predetermined sequence of steps. For example, a Retrieval Augmented Generation QA system (that we explored in previous sprints) might always follow the same flow: retrieve relevant documents -> have LLM read them and answer - this is a fixed chain of actions. An agent, however, has autonomy to choose its next steps. It can analyse its environment (inputs, context), make decisions about what to do, and execute tasks using tools or APIs without constant human guidance. In short, an agent designs its own workflow to achieve a goal, without needing a hard-coded one.
Key characteristics that distinguish agents from basic LLM applications include their autonomy and reasoning. They can handle branching decisions, invoke external tools or functions as needed, and iterate on tasks until a goal is reached.
The Agent Decision Loop
At the core of an agent's ability to autonomously perform tasks is a continuous decision loop, often described as a Think-Act-Observe cycle. This loop is what allows the agent to handle multi-step tasks and adapt based on intermediate results. Here is how you break the cycle down:
- Think - The agent (via the information provided to the context window of an LLM) analyzes the current situation - this includes the user’s request, any context or memory of past interactions, and the results of any previous actions. In short, the LLM “thinks” by generating some reasoning about what to do next. In practical terms, this might involve the model considering possible tools or solutions in its internal chain-of-thought.
- Act - Based on its reasoning, the agent decides on an action. This could be calling an external tool (for example, a search API, calculator, database query, etc.), or it could decide that it has enough information to provide a direct answer. The chosen action is then executed. If it is a tool, the agent (application with an LLM at its core) provides the necessary input to that tool (often formulated by the LLM). If it's a final answer, the agent outputs that answer to the user.
- Observe - After the action, the agent observes the outcome. If a tool was called, the agent gets back the tool’s result (e.g., the search results, calculation output, etc.). This result is then incorporated into the agent’s state or memory. The agent looks at this new information and evaluates if this action moved it closer to the goal or maybe the agent now has the final answer.
These steps then run in the loop - the new information from the observation is fed into the next Think step, and the cycle repeats. The agent would keep iterating through Think -> Act -> Observe until it determines that the goal has been achieved or no further actions are worth the effort.
This loop-based design is what enables dynamic problem solving - an unbounded set of user intents can be tackled by a single agent. For example, if a user asks a complex question, an agent might think and realize it should search a database, act by querying a search tool, observe the results, then think again with those results in context to decide the next step. It will continue this way, perhaps invoking multiple tools, until it can confidently answer the user.
For practitioners who like explanation in code, here is a pseudocode snippet of what a basic agent loop actually is:
state = {"messages": [ {"role": "user", "content": user_question} ]}
while True:
# 1. Think: LLM decides next step
output = LLM(state) # LLM is prompted with the conversation/history in state
if output.indicates_tool_use:
tool_name, tool_input = parse_tool_call(output)
# 2. Act: execute the chosen tool
tool_result = call_tool(tool_name, tool_input)
# 3. Observe: incorporate tool result into state
state["messages"].append({"role": "tool", "content": tool_result})
# Loop continues with new information in state
else:
# If output is a final answer
answer = output.final_answer
break
print("Agent's answer:", answer)state = {"messages": [ {"role": "user", "content": user_question} ]}
while True:
# 1. Think: LLM decides next step
output = LLM(state) # LLM is prompted with the conversation/history in state
if output.indicates_tool_use:
tool_name, tool_input = parse_tool_call(output)
# 2. Act: execute the chosen tool
tool_result = call_tool(tool_name, tool_input)
# 3. Observe: incorporate tool result into state
state["messages"].append({"role": "tool", "content": tool_result})
# Loop continues with new information in state
else:
# If output is a final answer
answer = output.final_answer
break
print("Agent's answer:", answer)A reasoning loop is an alternative to crafting explicit prompt chains and allows the agent to break a complex task into smaller steps (by itself), use external information as needed, and handle situations where a single LLM response might not be sufficient. This enables agents to solve tasks like multi-hop question answering, tool-augmented reasoning, or any scenario where intermediate results inform subsequent actions but the reasoning chain can not be defined beforehand.
Important note: unfortunately, it has been empirically shown that the more general the agent becomes, the less it is capable to solve complex tasks. Also, the longer the reasoning cycle takes place, the less accurately the final intended outcome can be achieved.
Key Components of an LLM Agent
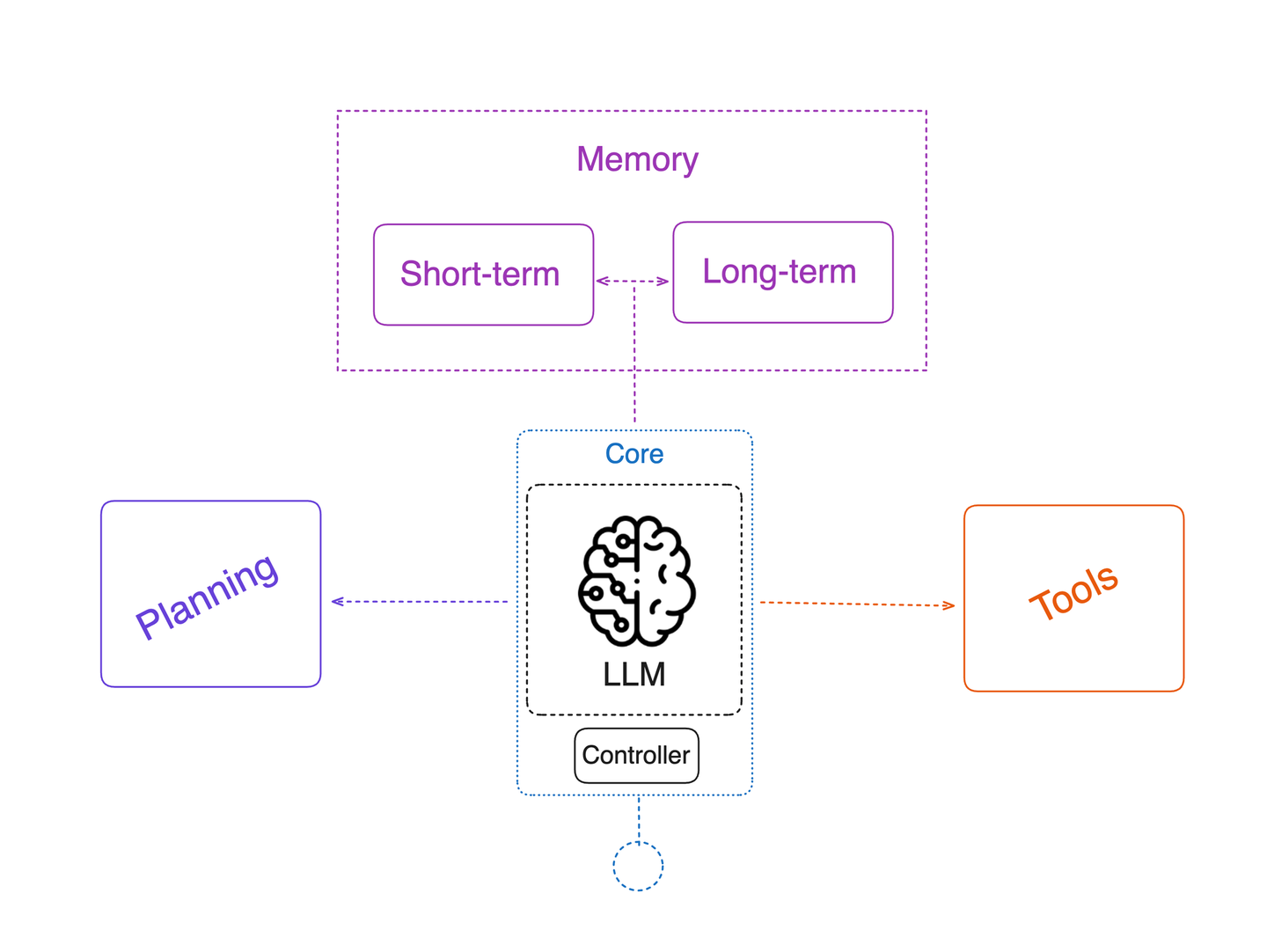
Building an agent that is described above requires a few core components working together. These pieces are: Tools, Memory, and the LLM (reasoning engine). Additionally, oftentimes we see Planning come up in agent design diagrams (in many implementations the LLM’s chain-of-thought is the planning with some additional elements like how many iterations of thinking are allowed).
- LLM (Reasoning Engine) - The Large Language Model itself is the brain of the agent. It generates the Thoughts and decides on Actions in the loop. The agent’s effectiveness heavily depends on prompting the LLM correctly to follow the desired format (e.g. thinking vs acting) and on the capabilities of the model. You might give the LLM a prompt like: “You are an AI agent with access to tools. When needed, you can output an action in the format [TOOL_NAME]: [INPUT]. Otherwise, answer the question”. This prompt engineering guides the LLM to produce either an action or an answer. If you are building tool calling from scratch you would generally output tool call instructions as part of structured outputs for Pydantic models that are then outputted by your LLMs. Many modern LLMs also have built-in support for tool usage (also called function calling discussed in the previous sprint) where the model can output a structured invocation of a tool.
- Tools - In the context of an agent, tools are external functions or APIs the agent can use to get information or execute tasks that the LLM itself cannot do via text generation. E.g. typical tools include web search, database queries, calculators, code execution or any custom API (weather service, etc.). By giving these tools to an agent, we greatly extend its capabilities beyond its trained knowledge. Also, in most cases it is best practice to use tools rather than purely rely on LLM’s parametric knowledge as it helps avoid hallucinations. Tools are usually implemented as callable functions. The agent (LLM) decides if and when to call a tool, and with what arguments, based on the user request and intermediate needs. For instance, if asked a math question, the agent might call a calculator tool. If asked about recent news, it might call a search tool. Tool outputs become observations that the LLM can then incorporate in its next thinking step. Designing the interface for tools is important - the LLM needs to know what the tool is and how to call it. This is often performed by properly describing functions, parameters and potential outputs of the tool. LLM orchestration frameworks make tool integration easier by removing the need of parsing out the function descriptions by yourself and also taking care of tool execution and passing of the outputs back into the LLM reasoning loop.
- Memory - Agents often need to remember information across turns of the loop or across an entire conversation/session. Memory is critically important for agents, as it enables them to retain and use information from previous steps. There are generally two kinds of memory:
- Short-term memory (or working memory) - This is information remembered during the course of a single task or query. In short, all the messages and observations collected in the state during the loop serve as short-term memory. The agent’s prompt grows with each loop iteration - earlier conversation and tool results are included so the LLM can refer back to them. This way, the agent doesn’t forget what it already tried or found out. Short-term memory usually lives in the prompt (or an internal state object) and is reset after the task completes.
- Long-term memory - This refers to persistence of information across separate sessions or long durations. For example, an agent that can remember facts about the user from past conversations, or recall what happened last week. Long-term memory might be implemented by storing data in a vector database, or using a specialized memory service, and retrieving relevant pieces when needed. In the context of a single agent session, long-term memory might not be that critical, but if you continue building agents that interact repeatedly with the same user or between each other, it becomes very important.
Memory management can get complex, you have to balance keeping important information vs. not overflowing the LLM’s context window. Various strategies (like summarizing old events or using retrieval of stored info) are used to handle this, but that’s a more advanced topic for a dedicated section.
- Planning (and Stopping Criteria) - Planning is the ability of the agent to set a multi-step approach to a complex goal. In many LLM agents, explicit planning (like first devising a complete plan then executing) isn’t separated, instead the LLM implicitly plans step-by-step during the Think phase. However, some architectures do include a separate planning step where the agent might outline the steps before execution (a good example could be Deep Research Agents where in many implementations we first plan the outline of the output report and then each of the paragraphs is researched separately by employing a sub-agent system). Regardless, the agent needs a criterion for when to stop planning and start executing, and when to stop the whole loop. The loop should terminate when the agent decides it has gathered enough information or completed the task to provide the final answer. Often the LLM will output a special token or format indicating “Final Answer” to signal completion (E.g. setting a dedicated field in your Pydantic model to True). Tuning this stopping condition (to avoid infinite loops or premature stopping) is part of agent design.
In summary, an LLM-based agent consists of an LLM that can reason and decide, a set of optional tools it can use, a memory/state to remember what has happened, and a decision loop (controller logic) tying these together. This week we will be going in depth into these moving pieces.
Overview of Agent Architectures and Patterns
Agentic System design patterns is a topic for next week, but this week I will still be including a short section on high level Agent Architecture patterns that more specifically target single agent architectures.
In general, there are varying levels of complexity in how much control we hand over to the LLM. In the simplest form, an agent might just make one single decision. When going more complex, it might handle many steps with branching logic. Here are a couple of common patterns:
- Router Agent (Single-Step Decision) - This is an agent that makes only one decision in a turn. For example, a router might examine a user input query and decide if it can answer straight or it needs to route the query to a sub-chain that would be executing a RAG pipeline. The LLM’s role is only to route or classify the request, and then the agent stops. This is a limited form of agent - the LLM’s control is narrow (one step, picking from predefined options). It’s useful for directing queries (say, to the correct knowledge base or skill) but not for multi-step problem solving. The output is structured in a way that the system can interpret and execute directly.
- ReAct / Tool-using Agent - The more general agent architecture is one that allows multi-step decision-making plus tool use. The ReAct framework (Reason+Act) is such an example - the LLM produces thoughts and actions to solve a task. In this pattern, the LLM might output something like: “Thought: I should search for relevant information. Action: Search[‘query about X’]”. The system executes the search and returns an observation, which the LLM then sees, and the cycle continues. ReAct introduced the idea that the same model output can contain both reasoning and an action that the system can execute. Modern agents often follow this approach, whether explicitly or under the hood. This tool-calling agent is almost exactly what was described in the decision loop earlier. It expands the LLM's control to not just one decision, but a sequence of decisions, and grants it the ability to use multiple different tools as needed. Along with that, it incorporates memory to keep track of prior steps, and potentially some other data as the task unfolds. This flexible architecture enables dynamic problem-solving far beyond a single-turn answer.
- Self-Reflection and Correction - Additional improvement to the multi-step agent is its ability to reflect on its own output quality and correct itself. E.g. After completing a solution, an agent might review its answer or consider if the answer could be wrong and then decide to try a different approach (this is often called the Reflection or Reflexion pattern). Potentially, an agent might detect that the answer is likely incorrect or incomplete, and loop again (or roll back) to fix it.
- Multi-Agent Systems - In advanced scenarios, you might have multiple agents cooperating or specializing (one might plan a task, another might execute or they handle different subtasks in parallel). These go beyond a single decision loop, but the main principles remain - each agent likely still has its own loop or they communicate through shared memory or a coordinator. Multi-agent orchestration is powerful for complex workflows (e.g. Deep Research Agents). We won’t dive deep into multi-agent setups this week, but be aware this is an emerging field that is likely to become more important as we move into the future.
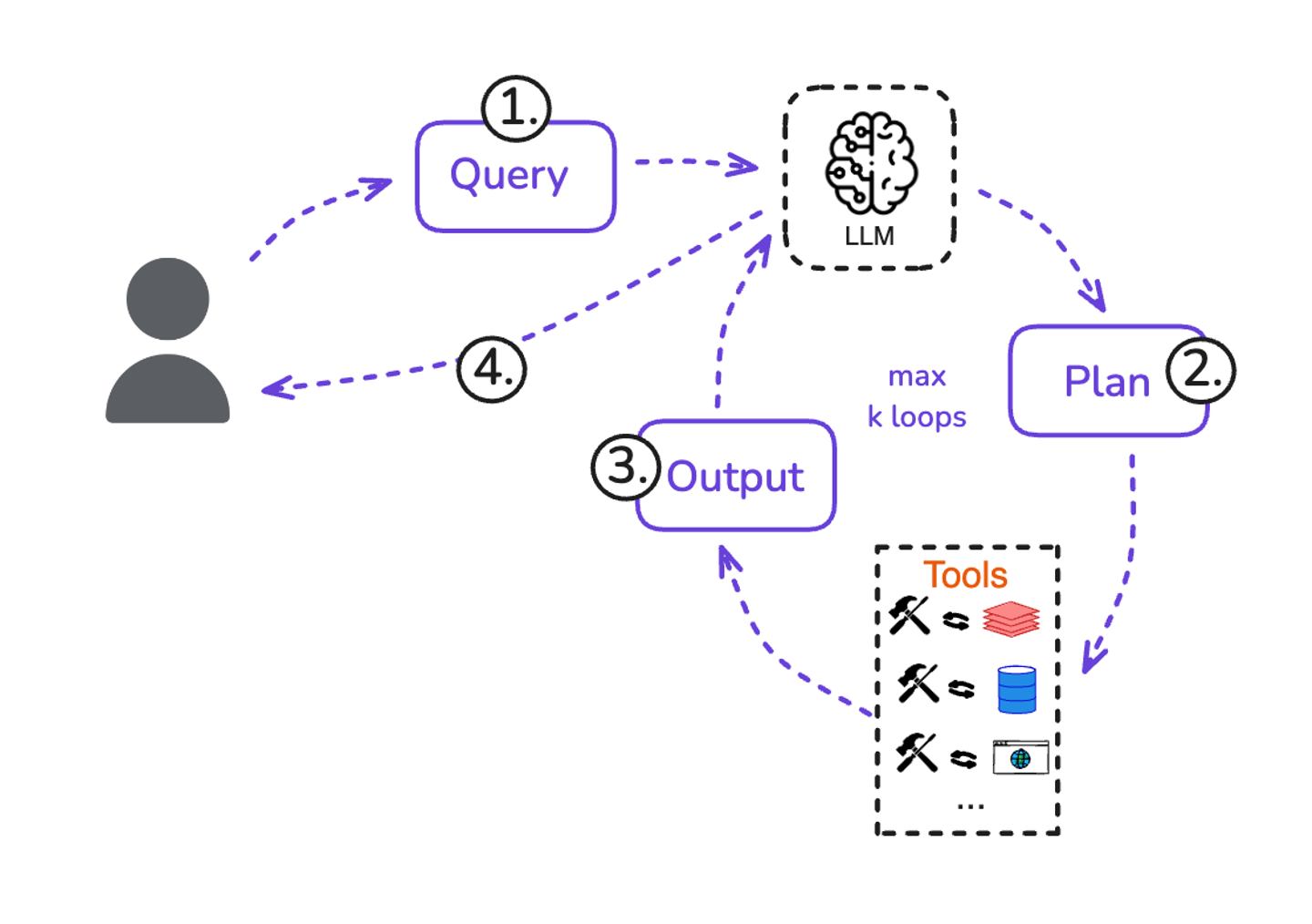
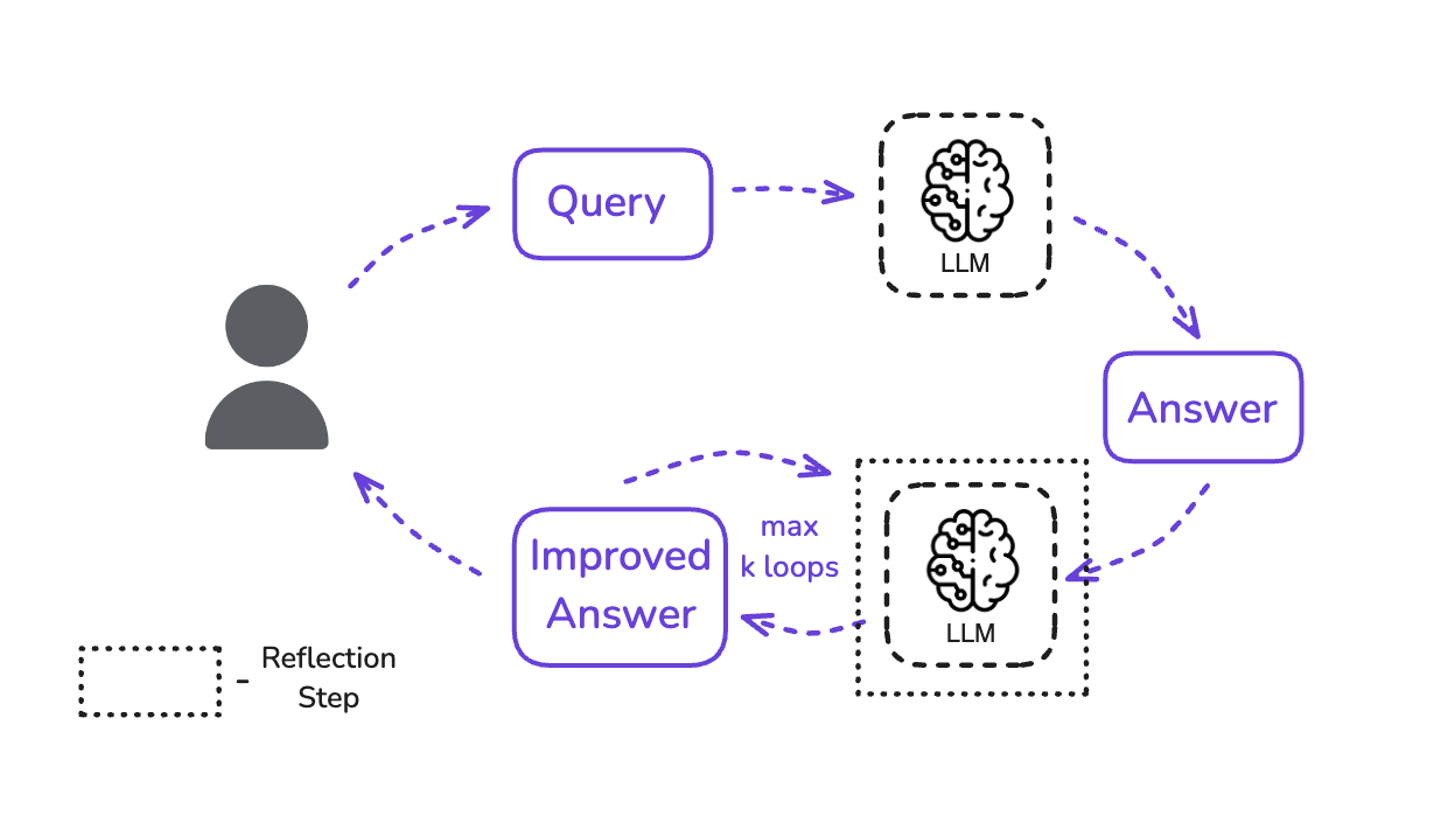
As you design an agent, choosing the right architecture means balancing how much autonomy the LLM gets versus where you put constraints. Simpler patterns (like router or single-tool call) are easier to control and interpret, while complex patterns (like free-form multi-step agents) are more flexible but can be harder to predict. The good news is that modern frameworks like LangGraph have started to provide abstractions for these patterns so you don't have to implement everything from scratch.



