
Jupyter Notebookは、データ分析や機械学習モデルの開発でよく使われるツールとなっています。多機能でインタラクティブな環境を提供する一方で、コードの可読性を確保することは、コラボレーション、コードのメンテナンス、将来の参照に不可欠です。
そこで今回は、データ探索や分析、機械学習モデルの可読性を向上させるために、私がこれまでに得たヒントやトリックを探ってみたいと思います。
1. 説明的な変数名と関数名を使用する
変数や関数には、意味のある、説明的な名前を選びましょう。こうすることで、他の人(そして将来の自分)が各コンポーネントの目的や機能を理解するのが容易になります。
2. コメントとドキュメンテーションを追加する
コードにコメントを入れることで、説明や文脈、あなたの思考プロセスへの洞察を提供することができます。さらに、ノートブックにマークダウンのセルを追加して、全体的なワークフロー、仮定、重要な観察についてのハイレベルな説明を提供することを検討してください。

3. 複雑なコードをより小さな関数に分解する
複雑なコードブロックがある場合、それを小さな関数に分割することを検討してください。これにより、読みやすさが向上するだけでなく、コードの再利用とモジュール化が促進されます。
#create a function to process dataframe for modeling
def preprocessor(dataframe):
X = dataframe[['トン数', '乗客数', '長さ', '船室']]
y = dataframe['乗組員']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3, random_state=22)
rob = RobustScaler()
rob.fit(X_train)
X_train_scaled = pd.DataFrame(rob.transform(X_train),
columns=rob.get_feature_names_out())
X_test_scaled = pd.DataFrame(rob.transform(X_test),
columns=rob.get_feature_names_out())
return X_train_scaled, X_test_scaled, y_train, y_test4. コードを整理する
コードをセクションやセルに整理することで、ノートブックの論理的な構造を維持することができます。ヘッダー、小見出し、マークダウンセルを使って、分析ステップとモデル開発プロセスの明確なアウトラインを提供します。
⚠️コツ⚠️
Jupyter Notebookの上部メニューバーに目次ボタンがあるのをご存知ですか? これをクリックすると、画面の左側にノートブックのセクションが表示され、クリックすることで直接セクションに飛ぶこともできます。

5. 行の長さを制限し、空白を使用する
長いコード行は読みにくくなります。行の長さは80文字程度を目安にし、適切な改行を行いましょう。また、空白を有効に使ってコードブロックを区切り、視覚的にわかりやすくしましょう。
⚠️コツ⚠️
変数の長いリストやキーと値のペアの辞書を書くときは、可読性を高めるために改行を使用します。
# list of models to try
models = [LinearRegression(),
Ridge(),
Lasso(),
ElasticNet(),
SGDRegressor(),
KNeighborsRegressor(),
SVR(kernel = "linear"),
SVR(kernel = "poly", degree = 2),
SVR(kernel = "poly", degree = 3),
SVR(kernel = "rbf"),
DecisionTreeRegressor(),
RandomForestRegressor(),
AdaBoostRegressor(),
GradientBoostingRegressor()]
# list of model names
models_names = ["linear_regression",
"ridge",
"lasso",
"elastic_net",
"sgd_regressor",
"kneighbors_regressor",
"SVR_linear",
"SVR_poly_two",
"SVR_poly_three",
"SVR_rbf",
"decision_tree_regressor",
"random_forest_regressor",
"ada_boost_regressor",
"gradient_boosting_regressor"]6. 不要なコードを削除する
定期的にコードを見直し、不要な行やブロックを削除しましょう。こうすることで、コードの乱雑さを解消し、ノートブックの全体的な読みやすさを向上させることができます。
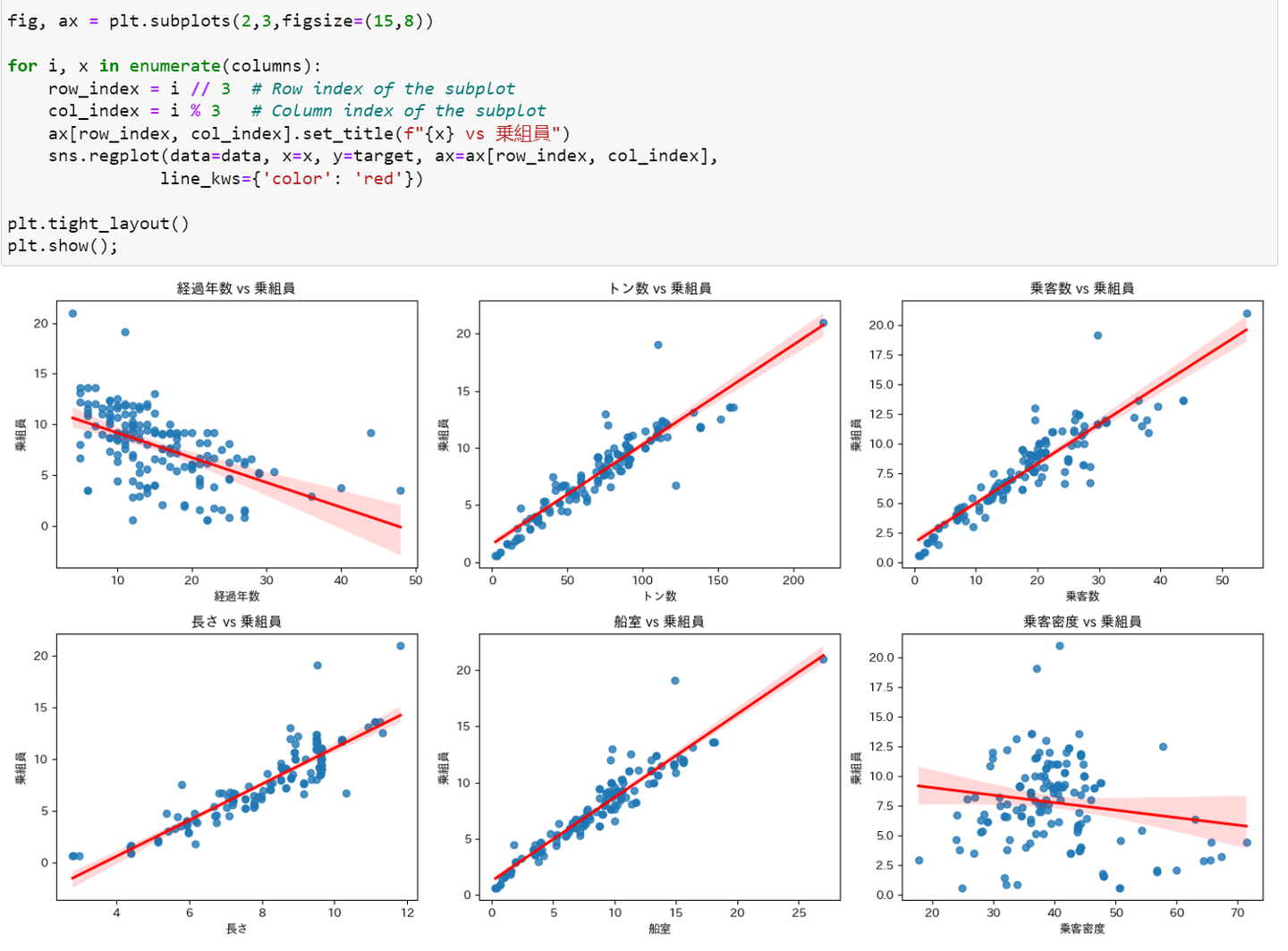
7. 意味のあるビジュアライゼーションを活用する
分析結果やモデルのパフォーマンスを提示する際には、洞察を効果的に伝える意味のあるビジュアライゼーションを選択します。明確なラベル、凡例、タイトルを使用し、ビジュアライゼーションが容易に理解できるようにします。
8. 結論を文書化する
データから導き出された結果を読者が理解しやすいように、最後のセクションまたはいくつかのセクションで解説を加えます。ハイライト、太字、斜体、箇条書きを使って、主要なポイントを明確にすることができます。

これらのヒントやトリックに従うことで、Jupyter Notebooksでのデータ分析や機械学習モデルの読みやすさを大幅に向上させることができます。明確でよく整理されたコードは、コラボレーション、コードのメンテナンス、自分自身や他の人による分析プロセスの理解を向上させることができます。

