
目的
エンジニアなら知識の入口を増やしたい。今回はIT系サイトに指定したキーワードで記事を収集してteamsに送信する。次回は記事の内容を要約したものを送信する様なツールに進化させたい
システム構成
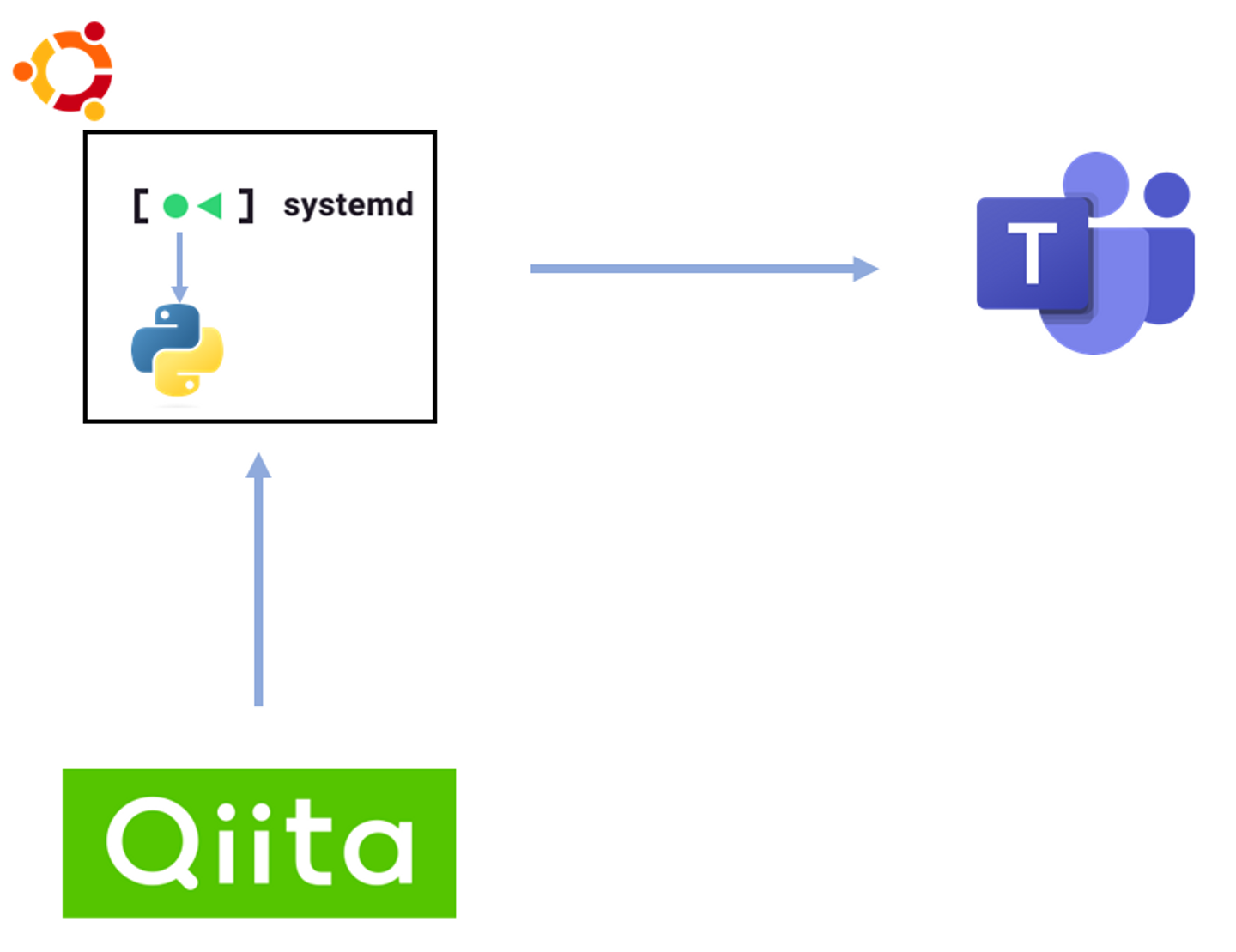
対象とそのクエリ分析
今回の対象はテストとして、qiitaのみとした。
コード本体
import re, openai, json, os, urllib.request, json, requests, random, time, pymsteams, time
from bs4 import BeautifulSoup
import pandas as pd
from urllib import request
teamsapi = os.environ["TEAMS_WEB_HOOK_URL"]
def qiita(keyword):
url="https://qiita.com/search?q="
pagerand = random.randint(1,50)
qurllist=[]
for page in range(10):
page = page + pagerand
mkurl=str(url) + str(keyword) + "&sort=rel&stocked=&page=" + str(page)
response = request.urlopen(mkurl)
soup = BeautifulSoup(response, 'html.parser')
response.close()
tag_list = soup.select('a[href].style-1lvpob1')
for tag in tag_list:
tagurl = tag.get('href')
qurl="https://qiita.com/" + str(tagurl)
qurllist.append(qurl)
for url in qurllist:
response = request.urlopen(url)
soup = BeautifulSoup(response, 'html.parser')
response.close()
title=soup.find("title")
print(title.text)
teamssend(title.text, url)
time.sleep(20)
def zenn(keyword):
url="https://zenn.dev/search"
pagerand = random.randint(1,5)
qurllist=[]
tag_list=[]
for page in range(10):
page = page + pagerand
mkurl=str(url) + "?q=" + str(keyword) + "&page=" + str(page)
print(mkurl)
headers = { "User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0" }
request = urllib.request.Request(url=mkurl, headers=headers)
response = urllib.request.urlopen(request)
soup = BeautifulSoup(response, 'html.parser')
response.close()
print(soup)
#for element in soup.find_all('a'):
# eurl = element.get("href")
# eurl = "https://zenn.dev" + str(eurl)
# qurllist.append(eurl)
# print(eurl)
#print(qurllist)
#for tag in tag_list:
# tagurl = tag.get('href')
# print(tagurl)
# qurl="https://zenn.dev" + str(tagurl)
# print(qurl)
# qurllist.append(qurl)
for url in qurllist:
response = request.urlopen(url)
soup = BeautifulSoup(response, 'html.parser')
response.close()
title=soup.find("title")
print(title.text)
teamssend(title.text, url)
time.sleep(20)
def teamssend(title, text):
myTeamsMessage = pymsteams.connectorcard(teamsapi)
myTeamsMessage.title(title)
myTeamsMessage.text(text)
myTeamsMessage.send()
def insert():
keywordlist = ["kubevirt", "localstack", "awscli", "prometheus", "iac", "terraform", "openstack", "kubernetes", "docker", "aws", "cloud", "container","ubuntu", "packet", "network", "docker-compose", "packer", "SSO", "S3", "monitoring","vpn", "git", "github"]
for keyword in random.sample(keywordlist, len(keywordlist)):
print(keyword)
qiita(keyword)
# zenn(keyword)
insert()
serviceの作成
[Unit]
Description=
Documentation=
[Service]
Type=simple
User=root
Group=root
TimeoutStartSec=0
Restart=on-failure
RestartSec=30s
#ExecStartPre=
ExecStart=/home/shoma/ainews/ainews.sh
SyslogIdentifier=Diskutilization
#ExecStop=
[Install]
シェルスクリプトの作成
#!/bin/bash
export TEAMS_WEB_HOOK_URL="https://smetrocit.webhook.office.com/webhookb2/f4891809-6acc-4059-9ad2-e039bf192240@a2c3e6fc-a959-4d2f-b374-4593a068ff9c/IncomingWebhook/32554e25629e47c09456be77fd4e4b4c/40a95c6c-b84c-44be-b5af-dc08583d9f71"
while true
do
python3 /home/shoma/ainews/news.py
sleep 21600
done
解説
クエリ分析の結果からURLの作成
url="https://qiita.com/search?q="
pagerand = random.randint(1,50)
qurllist=[]
for page in range(10):
page = page + pagerand
mkurl=str(url) + str(keyword) + "&sort=rel&stocked=&page=" + str(page)
サイトのHTMLの取得
response = request.urlopen(mkurl)
soup = BeautifulSoup(response, 'html.parser')
response.close()
classがstyle-1lvpob1のhref属性持ちaタグの要素を抽出
抽出した結果はlocationで指定するので、ドメインを付けてあげる。
tag_list = soup.select('a[href].style-1lvpob1')
for tag in tag_list:
tagurl = tag.get('href')
qurl="https://qiita.com/" + str(tagurl)
qurllist.append(qurl)
抽出したURLのHTMLを取得
for url in qurllist:
response = request.urlopen(url)
soup = BeautifulSoup(response, 'html.parser')
response.close()
記事タイトルの取得
title=soup.find("title")
Teamsへ送信する関数へ送信
teamssend(title.text, url)
Teamsへ送信する関数
def teamssend(title, text):
myTeamsMessage = pymsteams.connectorcard(teamsapi)
myTeamsMessage.title(title)
myTeamsMessage.text(text)
myTeamsMessage.send()
Keywordの指定
keywordlist = ["kubevirt", "localstack", "awscli", "prometheus", "iac", "terraform", "openstack", "kubernetes", "docker", "aws", "cloud", "container","ubuntu", "packet", "network", "docker-compose", "packer", "SSO", "S3", "monitoring","vpn", "git", "github"]
keywordを順に関数へ送信
for keyword in random.sample(keywordlist, len(keywordlist)):
print(keyword)
qiita(keyword)
結果
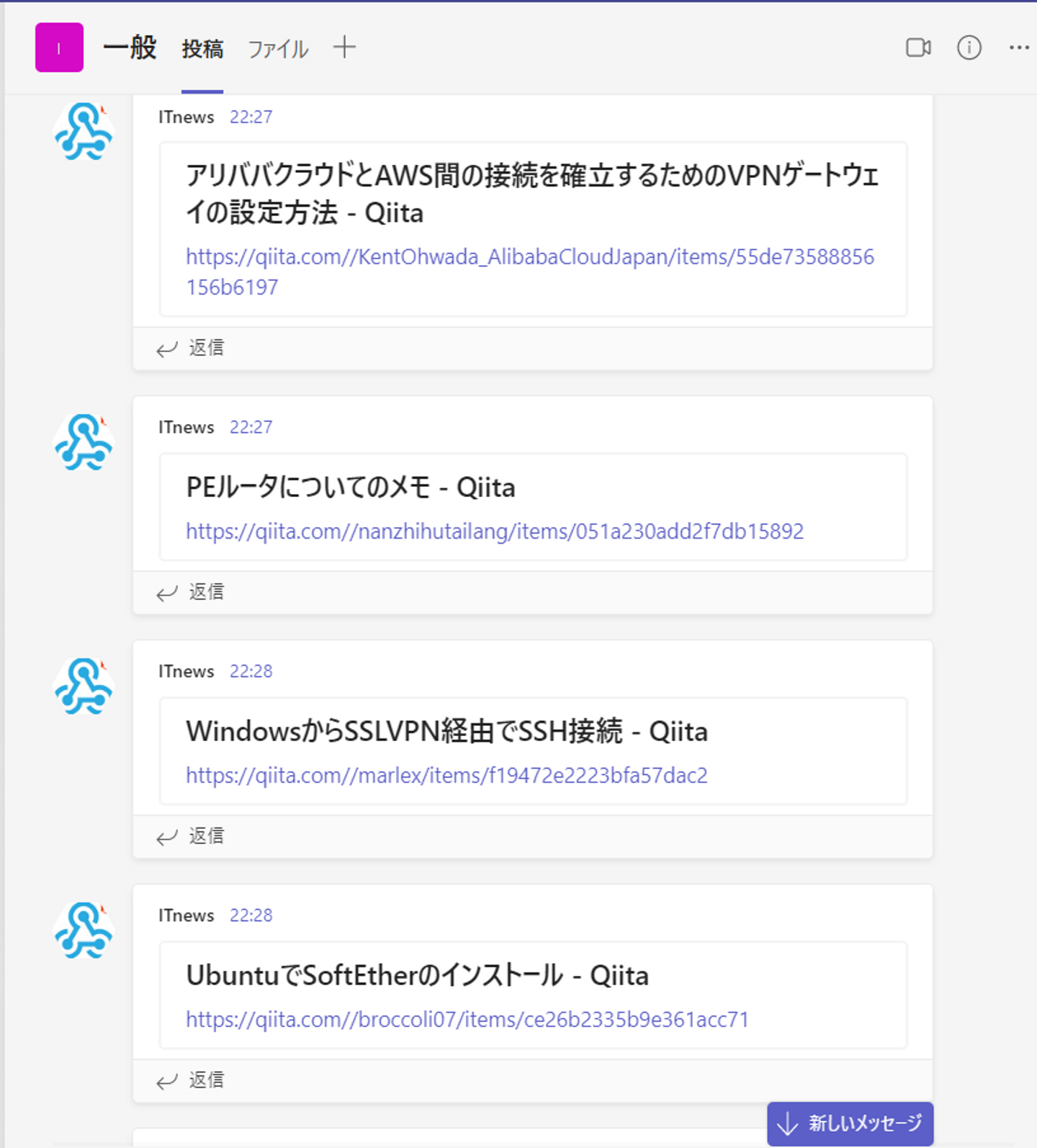
IT系サイトから特定のキーワードを含む記事を収集し、teamsに送信するツールの作成



