Discover companies you will love


Mid-career
Use foreign languages
Mid-career
Use foreign languages
Share this post via...
Keiichi Watanabe
新卒でgeechs(旧ベインキャリージャパン)入社。 入社後は一貫して、フリーランスエンジニアを支援する部署にて 法人営業、求職者のカウンセリングなどを担当。 これまでに、数百名のフリーランスエンジニアを支援。 2015年にスケールアウトに採用担当として入社。 統合後のSupershipホールディングスでも人事として新卒採用・中途採用全般に関わりながらHRBPも兼務。 2023年にエクサウィザーズに転職し採用部でテック採用に関わる。
ExaWizards Inc.'s members
新卒でgeechs(旧ベインキャリージャパン)入社。
入社後は一貫して、フリーランスエンジニアを支援する部署にて
法人営業、求職者のカウンセリングなどを担当。
これまでに、数百名のフリーランスエンジニアを支援。
2015年にスケールアウトに採用担当として入社。
統合後のSupershipホールディングスでも人事として新卒採用・中途採用全般に関わりながらHRBPも兼務。
2023年にエクサウィザーズに転職し採用部でテック採用に関わる。
What we do
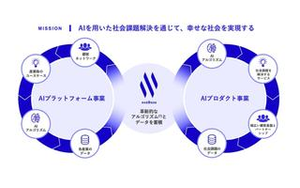
EXAWIZARDSは「AIを用いた社会課題解決を通じて、幸せな社会を実現する」という
ミッション実現に向けた2つの事業体
【 AIプラットフォーム事業】
顧客の経営課題解決に向け、AIプラットフォーム「exaBase」を基軸に年間250件以上のAI/DXプロジェクトを行っています。AIの理解促進~企画~設計・開発~運用・利用をワンストップで提案しており、すぐに使えるSaaSのAIアプリケーションや、AIアルゴリズム・API、MLOpsなど、AI/DXに関わる豊富なアセットを組合せることで、クイックなAI導入から共同でのサービス開発まで幅広いニーズに対応しています。さらに、DX人材・組織開発をワンストップで支援するサービスの提供や、AI/DXの推進リーダーが集う国内最大規模のコミュニティ運営などを通じて企業のAI活用/DX推進の内製化支援も行っており、全社課題の解決・顧客価値の最大化を支援しながら、AIの社会実装を推進しています。
【 AIプロダクト事業】
超高齢社会に代表される社会課題の解決に向け、AIプラットフォーム事業を行う中で抽出した汎用的な業界・社会課題を解決するためのAIプロダクトを開発・提供しています。社会課題に直結する介護・医療領域においては、介護スタッフの間接業務をAI × 音声入力でサポートするアプリ「CareWiz ハナスト」、5mの歩行動画から歩行者の転倒リスクをAIが解析するアプリ「CareWiz トルト」などを提供しており、プロダクトを広く展開することで蓄積したデータは性能の向上に利活用するだけでなく、AIプラットフォーム事業における個社課題の解決策の拡張にも還元しています。






What we do
ビジネスモデル全体像

AIプロダクト事業サービスラインナップ
EXAWIZARDSは「AIを用いた社会課題解決を通じて、幸せな社会を実現する」という
ミッション実現に向けた2つの事業体
【 AIプラットフォーム事業】
顧客の経営課題解決に向け、AIプラットフォーム「exaBase」を基軸に年間250件以上のAI/DXプロジェクトを行っています。AIの理解促進~企画~設計・開発~運用・利用をワンストップで提案しており、すぐに使えるSaaSのAIアプリケーションや、AIアルゴリズム・API、MLOpsなど、AI/DXに関わる豊富なアセットを組合せることで、クイックなAI導入から共同でのサービス開発まで幅広いニーズに対応しています。さらに、DX人材・組織開発をワンストップで支援するサービスの提供や、AI/DXの推進リーダーが集う国内最大規模のコミュニティ運営などを通じて企業のAI活用/DX推進の内製化支援も行っており、全社課題の解決・顧客価値の最大化を支援しながら、AIの社会実装を推進しています。
【 AIプロダクト事業】
超高齢社会に代表される社会課題の解決に向け、AIプラットフォーム事業を行う中で抽出した汎用的な業界・社会課題を解決するためのAIプロダクトを開発・提供しています。社会課題に直結する介護・医療領域においては、介護スタッフの間接業務をAI × 音声入力でサポートするアプリ「CareWiz ハナスト」、5mの歩行動画から歩行者の転倒リスクをAIが解析するアプリ「CareWiz トルト」などを提供しており、プロダクトを広く展開することで蓄積したデータは性能の向上に利活用するだけでなく、AIプラットフォーム事業における個社課題の解決策の拡張にも還元しています。
Why we do

代表取締役社長 春田 真 (元DeNA会長)

Chief AI Innovator 石山 洸 (元リクルートホールディングス メディアテクノロジーラボ 室長)
2045年、日本の人口動態は「50歳以上の人口が6割、50歳未満の人口が4割」となり、労働力不足はますます深刻化することが予想されます。
それでも日本が成長を続けるためには、現時点ではアカデミアの世界に篭っているAIの先端技術を企業に実装させることにより、企業や社会全体の生産性をあげる必要があります。AIの力を活用することで、人はより人らしく、自由に生きていけると私たちは考えます。
How we do

社内風景

●ボードメンバー
元DeNA会長・元DeNAベイスターズの球団オーナーを務めた春田真を中心とし、リクルートのAI研究所であるRecruit Institute of Technologyを設立し、初代所長を初代所長を務めた石山洸をはじめとするメンバーで構成されています。
https://exawizards.com/team/boardmember
●アドバイザー
人工知能の中でも各分野の第一人者の先生方がアドバイザーとして関わってくださっています。例えば、AI×ロボットであれば早稲田大学の尾形哲也教授など。
現在も最新の知見はアカデミアの世界に数多く存在しているため、エクサウィザーズでは新しいプロジェクトが始まるたびに各専門の先生方に相談に伺います。先生方と日々コンタクトを取りながら、最新の知見を実装できる環境が整っています。
https://exawizards.com/team/advisor
●エンジニア
20年前からAIを研究しつつ起業していたエンジニアもいれば、大学院を卒業してそのまま入社したエンジニアも、大手メーカーから転職してきたエンジニアもいます。未踏認定クリエイター、Googleに自分の会社をバイアウトしたエンジニアなど、技術力の高いエンジニアが所属しています。
https://speakerdeck.com/exawizards/introduction-of-exawizards-inc-engineer
●ビジネス
外資系戦略コンサル出身者や事業会社、大手ベンチャー企業など、さまざまな企業から多様な人材が集まっています。各個人がオーナーシップを持つ起業家の集合体のような組織で、自らが解きたい社会課題解決に向かって仲間を巻き込み、事業を作る経験ができるなど、最短で経営者・事業責任者を目指せる環境です。
https://speakerdeck.com/exawizards/introduction-of-exawizards-inc-bizdev
As a new team member
【職務内容】
As a Site Reliability Engineer, you will be responsible for developing solutions, implementing requirements, assisting in creating key processes and procedures, that facilitate product planning, execution and delivery. We aim to solve society's issues with AI, so our mission is to solve the Engineering Department's issues!
【必須要件】
Familiarity with at least one cloud platform (i.e. GCP, AWS, Azure, etc...)
Experience in designing and implementing scalable cloud-based solution architectures
Strong expertise in infrastructure-as-code solutions such as Terraform
Strong operational expertise in containerization technologies, especially Kubernetes
Knowledge of source control, CI/CD, infrastructure automation, orchestration, deployment automation and configuration management
Bi-lingual (business English & Japanese daily conversation or English daily conversation & Japanese native)
While our team is mostly english-speaking, you should be comfortable enough talking in Japanese with other internal stakeholders
【歓迎要件】
AWS Solutions Architect certifications or knowledge on par with those
Kubernetes development experience, such as creation of in-house Helm charts
Familiar with scripting languages (Shell, Python, Golang)
Familiar with extended infrastructure-related tooling such as Ansible or Chef
Experience in working with large software systems developed on Unix/Linux
Experience of working with monitoring and metrics systems (e.g Collectd, Grafana, Nagios, etc.)
Experience in working closely together with development, product and business teams
Knowledge of web application security and best practices
【求める人物像】
You are comfortable at explaining complex recommendations to engineering and infrastructure teams, while discussing technical trade-offs in product development with other work colleagues. You are highly resourceful, analytical, and have a combination of focus, flexibility, self-motivation, and integrity.
0 recommendations
Highlighted stories
More from ExaWizards Inc.
- 長期インターンシップ
学年不問 | 生成AIサービスのtoBマーケティングの経験が積めます!
- Techlead DIA
Tech lead Fullstack_AI×HR Techプロダクト募集
- 事業開発(DX人材育成領域)
事業開発/人材育成アセスメント領域 日本のDXを推進するAI×HRTech
0 recommendations
What happens after you apply?
- ApplyClick "Want to Visit"
- Wait for a reply
- Set a date
- Meet up
Company info
Founded on 02/2016
379 members
- CEO can code/
- Expanding business abroad/
- Funded more than $1,000,000/
- Funded more than $300,000/
〒108-0023 東京都港区芝浦4丁目2−8 住友不動産三田ファーストビル 5階