
株式会社Legalscape's job postings
はじめまして。Legalscape(リーガルスケープ)のCTOの城戸(きど)です。
私たちLegalscapeは法 × 情報技術のリーガルテック(LegalTech)と呼ばれる領域でプロダクトを開発・提供しているスタートアップです。
今は弁護士や企業で法務に従事する方をターゲットにした、リーガルリサーチを助けるプロダクトを作っています。
今日は、もう少し具体的に、どんなプロダクトを作っているのか、そしてどうしてこのプロダクトを作っているのかを紹介します。
そもそも私たちは何をやっているのか
ここ数年、日本のリーガルテック界隈はにわかに盛り上がりを見せており、リーガルテックという言葉を聞いたことがあるという方も多いと思います。
実は、一口にリーガルテックと言っても、情報技術を使って支援する対象の法務業務はさまざまです。契約書などの書面の作成・レビュー効率化だったり、対外的な契約締結の効率化だったり、社内ナレッジの管理支援だったり。それもあって、たくさんのリーガルテックスタートアップが登場してきています。
私たちLegalscapeは、その中で、リーガルリサーチの支援という切り口からプロダクトづくりに取り組んでいます。
リーガルリサーチとは、たとえば新しいビジネスモデルを立案したりするときの意思決定をサポートする法的な材料・根拠となる情報を調査、解釈し、判断につなげることを指します。
新しいビジネスのアイデアを思いついたとして、実行に移す前に「このスキームは適法なのか?」「何らかの規制に引っかからないか?」というようなことを法令をはじめ関連する文献を調べて確認しないと、問題が起こりかねません。
このリーガルリサーチは、弁護士をはじめとして法務に携わる人にとって、業務の根幹をなすと言っても過言ではないのですが、しかし、とっても大変なものなのです。
リーガルリサーチの大変さは、どういうところにあるのでしょうか?
リーガルリサーチ = 散在する大量の情報から探し出す
法と法務の周辺は、さまざまな情報が取り巻き、かつそれらは相互に関わりあっています。
たとえば法令です。
一つの法律をとっても、関連する別の法律や、施行令・施行規則というような下位の法令が多く存在することはご存知の方も多いでしょう。
法令だけでもそれだけいっぱいあるのに、関係する官公庁が出すガイドラインや指針といった文書に細かい取り決めがあることもありますし、解釈が問題になると、過去の裁判の判決や学者の見解、解説書籍などを参照しないといけない場面も少なくありません。
それらの多くは、官公庁のWebサイトだったり、紙の書籍だったり、論文誌だったり、さまざまな媒体に別々に存在しているため、それだけ多くの場所から必要なものを探し出すという大きな労力が必要な作業です。
一つの書籍を読んでいても、「通説では、……としている(コンメ (4) 928頁[城戸])」などと他文献への参照が出てくるので、次々と別の文献を探さないといけません。
こうして色々なところを探さないといけないだけでも大変なのに、紙の書籍は中身を検索できないし、官公庁のWebサイトも使い勝手はまちまちです。
総務省のe-GovというWebサイトで法律の条文を探したことがある方は分かるかと思いますが、国のWebサイトと言っても、今どきの検索サービス、最先端の検索技術が提供されているとは言い難いのが現状です。
Legalscape = legal + (land)scape
でも本当は、こうしたさまざまな情報源に散らばった大量の情報を扱うというのは、まさにコンピュータの得意分野だと思いませんか?
色々な情報が相互に参照しあっているなら、それがすべて集まって、一か所で検索出来て、リンクで繋がっている、そんなデータベースがあってしかるべきだと思いませんか?
それだけ自然言語で書かれた文書が大量にあるなら、自然言語処理の技術を応用して、リーガルリサーチをさまざまな角度から支援することが出来そうだと、想像できますよね。
この領域だったら、私たちのもつ情報技術の力で役に立つものが作れるはずだ。
そう思って私たちはLegalscapeを始めました。
法に関する (legal) 散逸した情報を、整理し、分析し、一目で見渡せる分かりやすい景色 (landscape) として描き出したい。
そんな思いを込めて私たちはLegalscapeという名前を選びました。
これまでにない新しい市場に挑む
たとえば、訴訟大国として知られるアメリカでは、判決をはじめとして多くのデータのオンライン公開が盛んに進められています。
そのため、多くのリーガルテック企業が生まれ、データがあることは前提としてそれをどう利活用するかの勝負となり、しのぎを削っています。
一方、日本はどうでしょうか?
私たちがリーガルリサーチという領域でプロダクトを作り始めたときは、多くの法律系出版社(そう、法律系出版社というのがあるのです)の書籍がオンラインで簡単に読めるようなサービスがあったわけでもなく、今も各社の書籍データの電子化状況はまちまちです。
また、官公庁の資料等は省庁ごと、部局ごとにそれぞれのルールで発行され、探すのも一苦労です。
データが整備されていなければ、データを利活用することはできません。
私たちは、法律分野でよいプロダクトを生み出し、本当に有意義なビジネスをするために、データの利活用以前に、泥臭くても、整理されたきれいなデータを作るところから取り組む会社になることを選びました。
正直に言って、いわゆる「AI」技術、機械学習技術を武器に素早く横展開して急拡大を目指す他の会社なら、法律分野を選ばないでしょう。
だからこそ、リーガルリサーチの苦痛を圧倒的に削減し効率化するプロダクトづくりは私たちにしかできないし、私たちがやるしかないと思っています。
本当に実務で役立つプロダクトを作る
弁護士発のリーガルテックスタートアップがほとんどの中、テクノロジーバックグラウンドから出発したLegalscapeは、はじめこそ異質な存在だったかもしれません。
法務領域という「お堅い」業界の中で、私たちは知らないことだらけの状態からスタートしました。
それでも、多くの方の助けを借りながら、商用判例データベース向けの特許ライセンス提供による「Legalscape QuickReader for 判例体系」 (PDF) をリリースしたり、またリーガルリサーチツール「Legalscape」のクローズドβ版を提供開始したりしてここまで来ました。
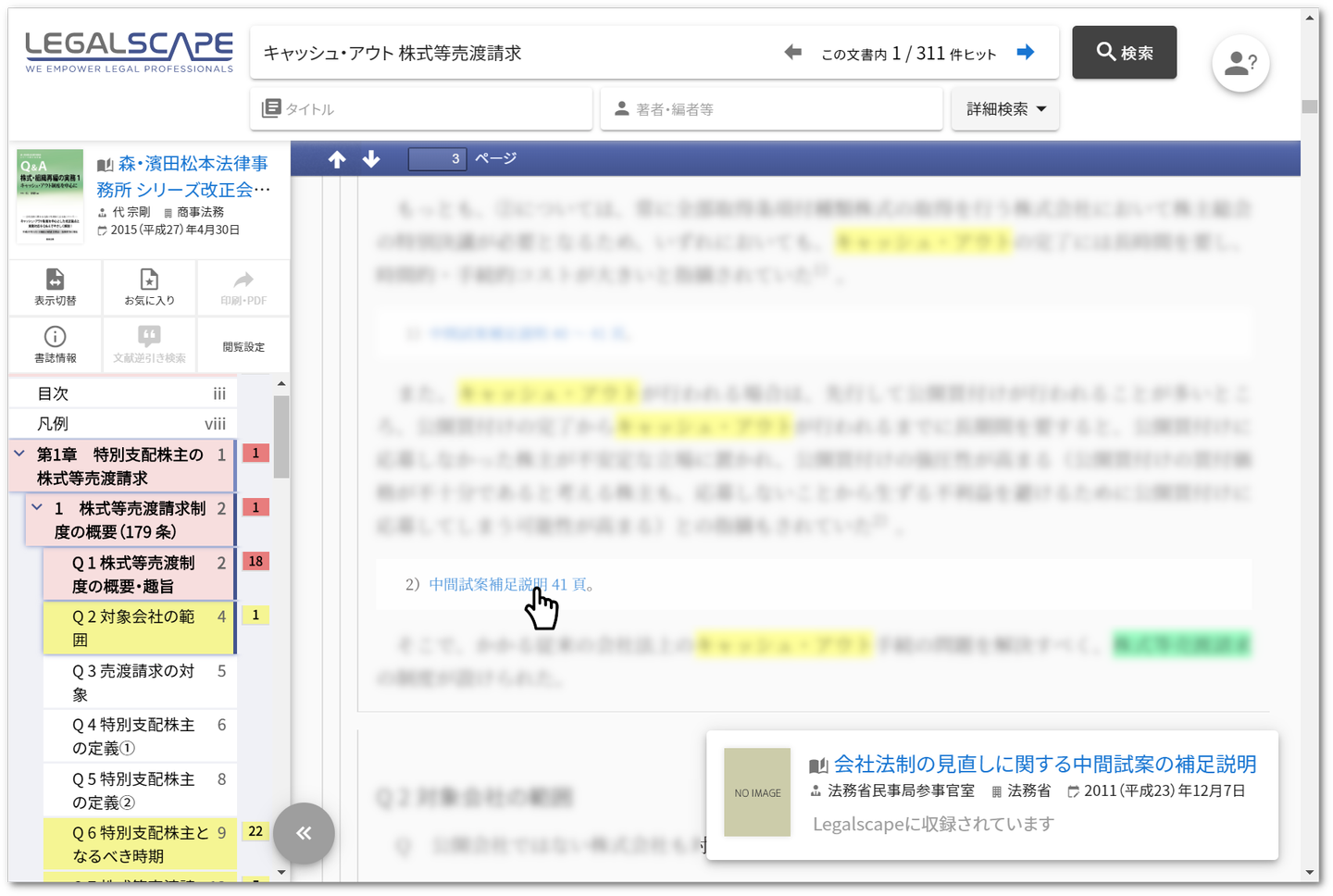
リーガルリサーチツール「Legalscape」は日本の四大法律事務所の一つ森・濱田松本法律事務所や、大手ITメガベンチャーで既に実務に使っていただきながらフィードバックをもとに改善をし続けているところです。
こうして私たちが目指すビジョンを理解していただける方が増えてきていて、事業としても成長中であるというのは素直に嬉しいです。
大変なプロダクトづくりですが、自信をもって役立つものを作っていると思えること、また実際に使ってくださっている方からダイレクトに声を聴けることが私たちにとって大きなモチベーションの一つになっています。
Legalscapeは採用を強化します
Legalscapeはまだ少数精鋭のチームです。
プロダクトが多くの方に使われ、さまざまな声を伺う中で更にまた新しい方向性に気づき、どんどん未来の可能性が膨らんできました。
そんな中、さらなる可能性を探しつつも、いよいよ目指す方向へ向けて成長をさらに加速させるために、Wantedlyをはじめとして採用を本格化させることを決めました。
もともと私は、リーガルの分野とは何の縁も無い、コンピュータ科学方面の人間でした。学生時代はアルバイトとしてpairsのeurekaやVorkers(現・オープンワーク)で勤め、Web開発やデータ分析をしていました。また、東京大学の大学院と国立情報学研究所というところで、自然言語処理分野の研究をしていました。
そんな私がMicrosoftをやめて起業し、WebとNLPで便利なものを作るぞと意気込んでいたら、業界の複雑な構造を学び、法を取り巻くデータの現状を知り、こんなにも、それ以前の段階にやらないといけないわけのわからないことがいっぱいあったとは……ということを思い知って苦闘しています(僕最近PDFパーザ書いてるんですよ。意味わかんないけど)。
考えてみると、こういうカオスが、Legalscapeではたらくことの特徴かもしれません。
会社とプロダクトの成長のためにあらゆることに挑み、エンジニアだったりBizDevだったりといった役職にすらとらわれることなく、いわば総合格闘技に取り組む。
今まさに圧倒的成長中のチームで、自分の持てる力をフルに使って、一緒に世界をよくするいいものを作ってみませんか?
カオスを楽しめるあなたのご応募をお待ちしています。
Legalscapeでは、情報技術の力で法領域の課題を解決するためにエンジニアを募集しています!
まずはカジュアルにお互いの話をするところから始めたいと思っていますので、気軽にご応募ください!
はじめまして、Legalscapeです








