

【スタッフノート】クラシコムではほとんど誰もグラフを描かない? | クラシコム
2019年のはじめにクラシコムに転職して最初の1〜2ヶ月は、仕事が終わると脳みそがクタクタに疲れていました。 前職の化学メーカーと違って、実験の設備がないことは理解していましたが、仕事をしていて、社内のほとんど誰も、グラフを描かないんです。いつも、自分たちの感覚を言語化して議論が行われています。 ...
https://kurashi.com/journal/11111
こんにちは。ビジネスプラットフォーム部の高尾です。データ分析や、物流、カスタマーサポート、情シスを担当しています。
データ分析においては、いつも、テクノロジーグループのスタッフに助けてもらいながら業務を進めていまして、今日はこのnoteにお邪魔して記事を書きに来ました。
僕自身は、バックグラウンドが化学の研究開発なので、グラフを書くことは大好きでした。
そして、クラシコムに入社してから勉強して、SQLとLookMLは書けるようになったけれど、コードは書くことができない、というスキルセットを持っています。入社以来、社長室に所属して経営に近いところにいたので、KPIの設定や、どういう数字をどうみたいか?というところの勘所を経営陣と密にコミュニケーションできた、という立場から、データ分析を担当することになってきました。
僕が入社した2019年春ころから、徐々に「北欧、暮らしの道具店」のデータ分析基盤について整備を進めてきまして、関係者も増えてきたこともあり、経緯を含めて現状を整理したいと考え、この記事を書くことにしました。
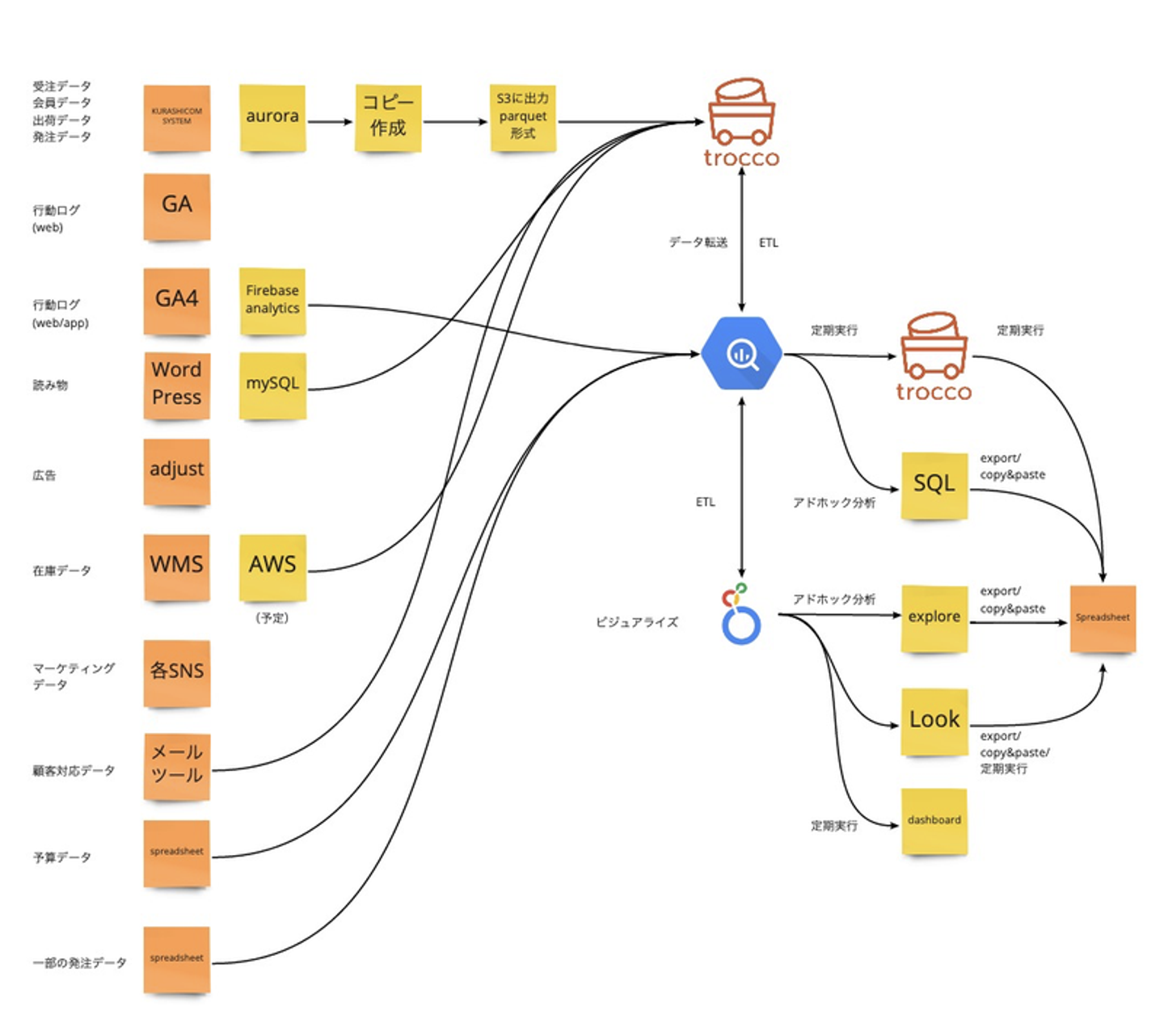
クラシコムには、主に下記のような形でデータが保持されています。
・クラシコムシステム:いわゆる基幹システム。受注データ、会員データ、出荷データ、発注データなどを保持。
・Google Analytics:web上の行動データ
・Google Analytics 4:web、アプリ上の行動データ(2019年11月ころから稼働)
・WordPress:読み物のデータ
・Adjust:アプリ広告のデータ
・WMS(Warehouse Manegement System):倉庫の在庫データ
・メールツール:顧客対応データ
・Google Spreadsheets:予算数字や一部の発注データなど
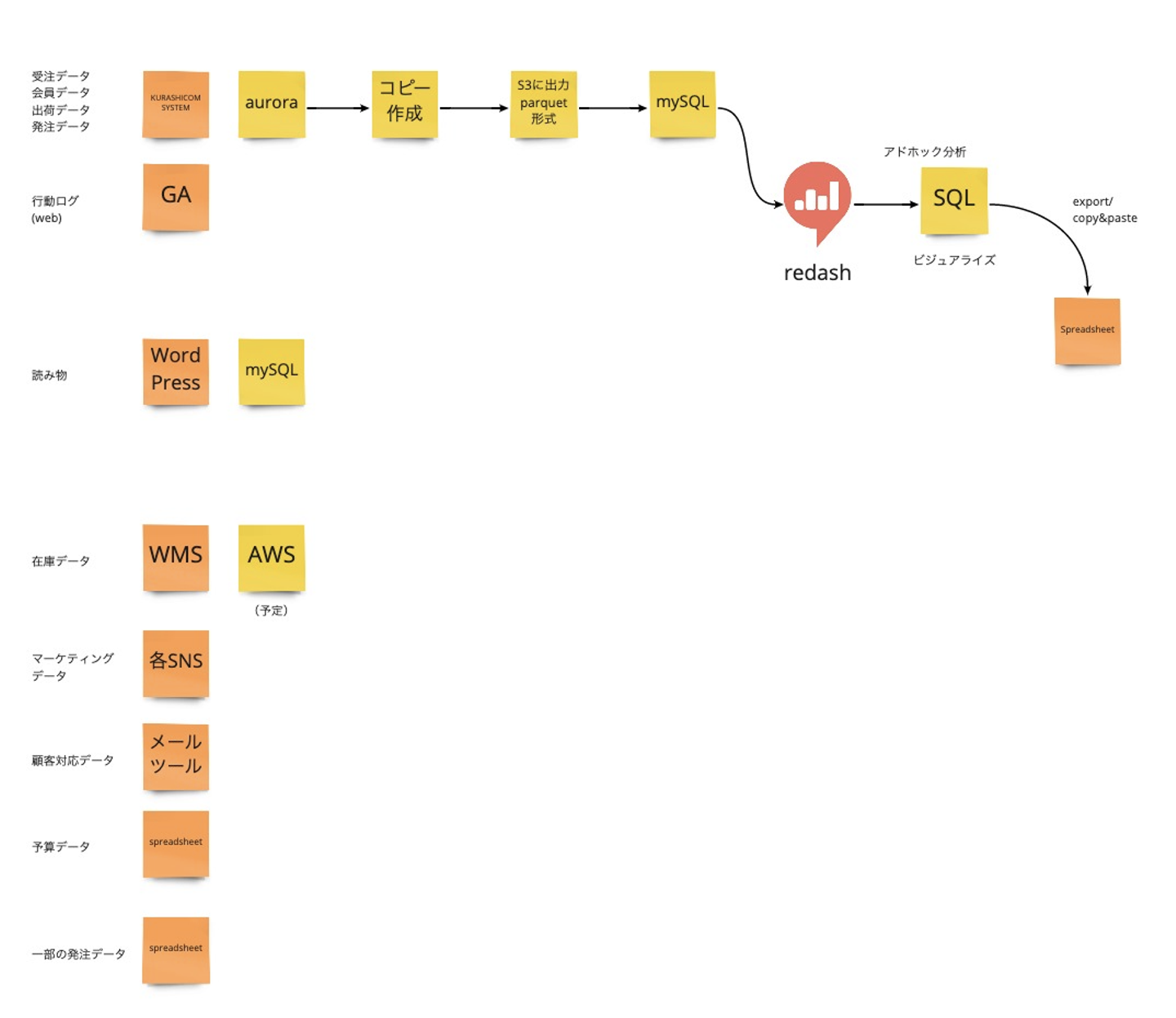
「北欧、暮らしの道具店」の基幹システムのデータをMySQLに保存し、それをRedashからSQLによって分析、集計する、という環境が整っていました。
社内で、経理、バイヤー、社長室の僕が、それぞれの業務にクラシコムシステムのデータを活用するために、独学でSQLを勉強し、データ分析を始めたのが、クラシコムでのデータ分析のはじまりです。
このときは、分析対象とできるのはクラシコムシステムのデータと、Google Analyticsのコンソール上で得られるデータに限られていました。MySQLのバージョンも古かったことから、window関数が使えない!とか、分析の時間がかかりすぎて、複数年度に渡った分析では、queryがtime outする、という事象が発生していたものの、どうしたらいいのかわからない、という状態でした。
↑データ分析立ち上げのころ。対象としていたデータが少ない・・・
独学組でのデータ分析に限界を感じ、「先生役」となる方を探し、その方の知見を元にしたデータ分析や、クラシコムが目指すべきデータ基盤像の構想を練ってきました。
その中で、「Looker」を軸にした環境構築がクラシコムにフィットしていそうだ、というところがみえてきたので、導入に踏み切りました。
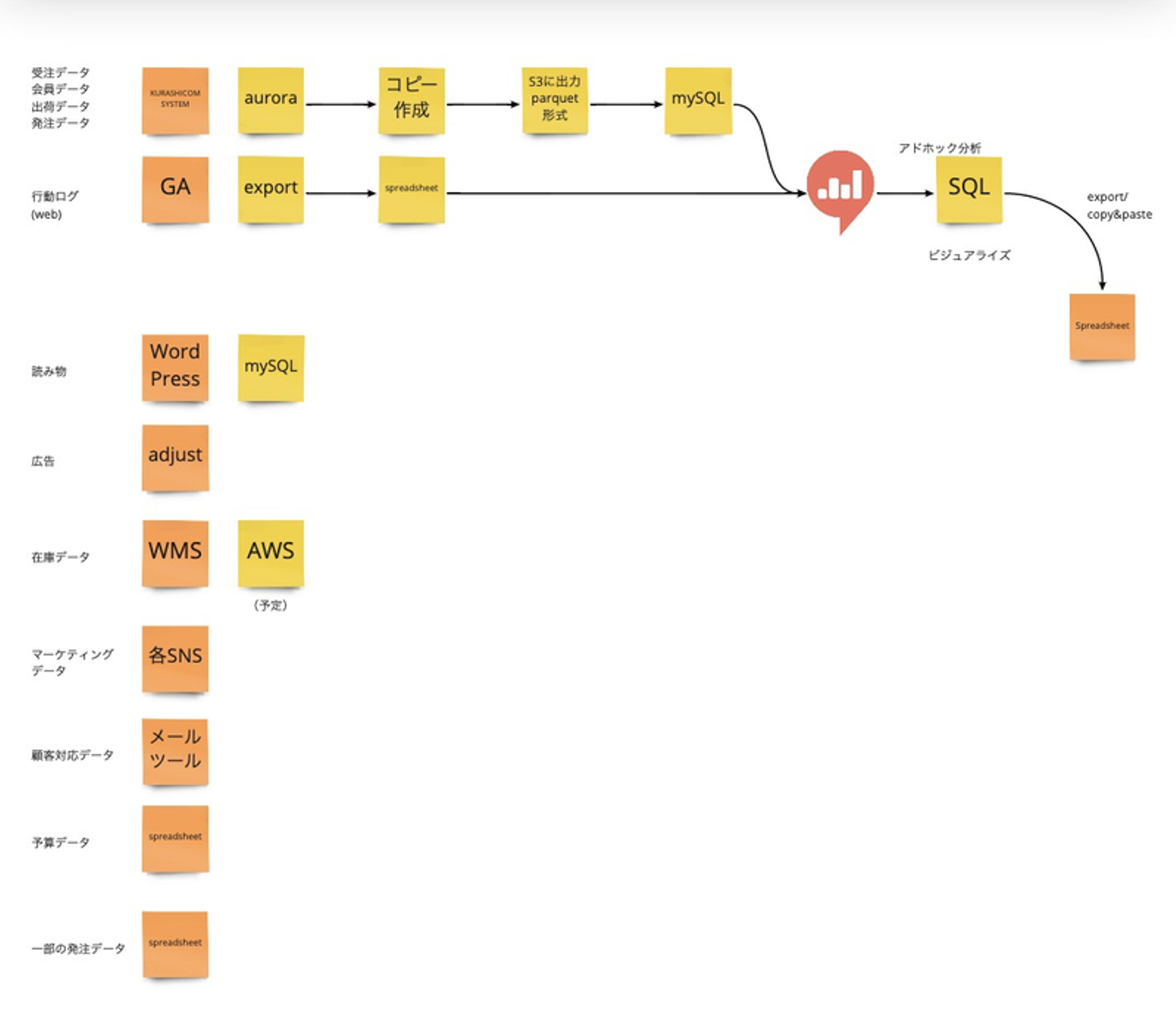
Google analyticsのデータをSpreadsheetsに集約することで対象を拡大。
対象の拡大による利便性と、Spreadsheetsをデータマートとして使うことの限界を早くも感じていた時期でした。
導入の詳しい経緯は、Lookerさんの事例紹介にてインタビューいただいたのでそちらを御覧ください。
この当時のデータ分析チームの構成としては、データ担当の僕、データアナリスト(業務委託)、インフラ〜データエンジニアの知見のあるエンジニア(業務委託)という構成で、必要に応じて、テクノロジーグループのスタッフに手助けをしてもらっていました。
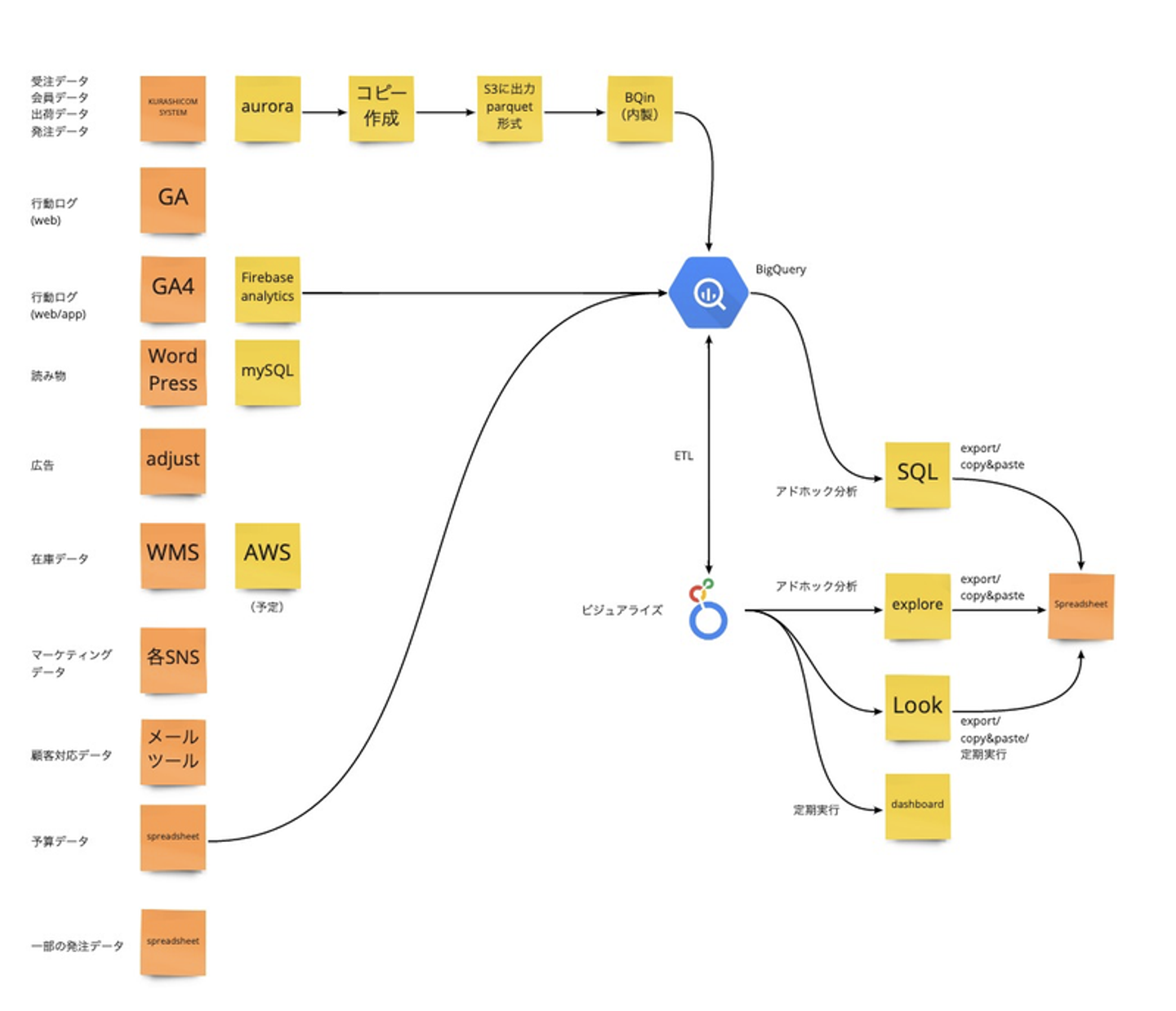
エンジニアリングリソースが潤沢にある状況ではなく、一方で、分析者は複数名いたので、データガバナンスを効率的に担保するツールとして、Lookerを選びました。また、データはできるだけ一箇所に集約したほうがいい、という指針を元に、Lookerとの相性のよさも踏まえて、BigQueryをデータウエハウスとして選択しました。
Lookerの導入によって、分析環境の安定化が実現され、自由度の高いダッシュボードも構築できたことによって、経営陣にも好評を得ました。
今では、データアナリストの業務委託は二人に増えました。また、前述したSQLを書けるバイヤーにもデータ分析に関わってもらうようになったことで、分析対象を、経営の上流に関わる数字だけでなく、商品ごとの売上や、日々のお客様の動きにまで関心の対象を広げています。
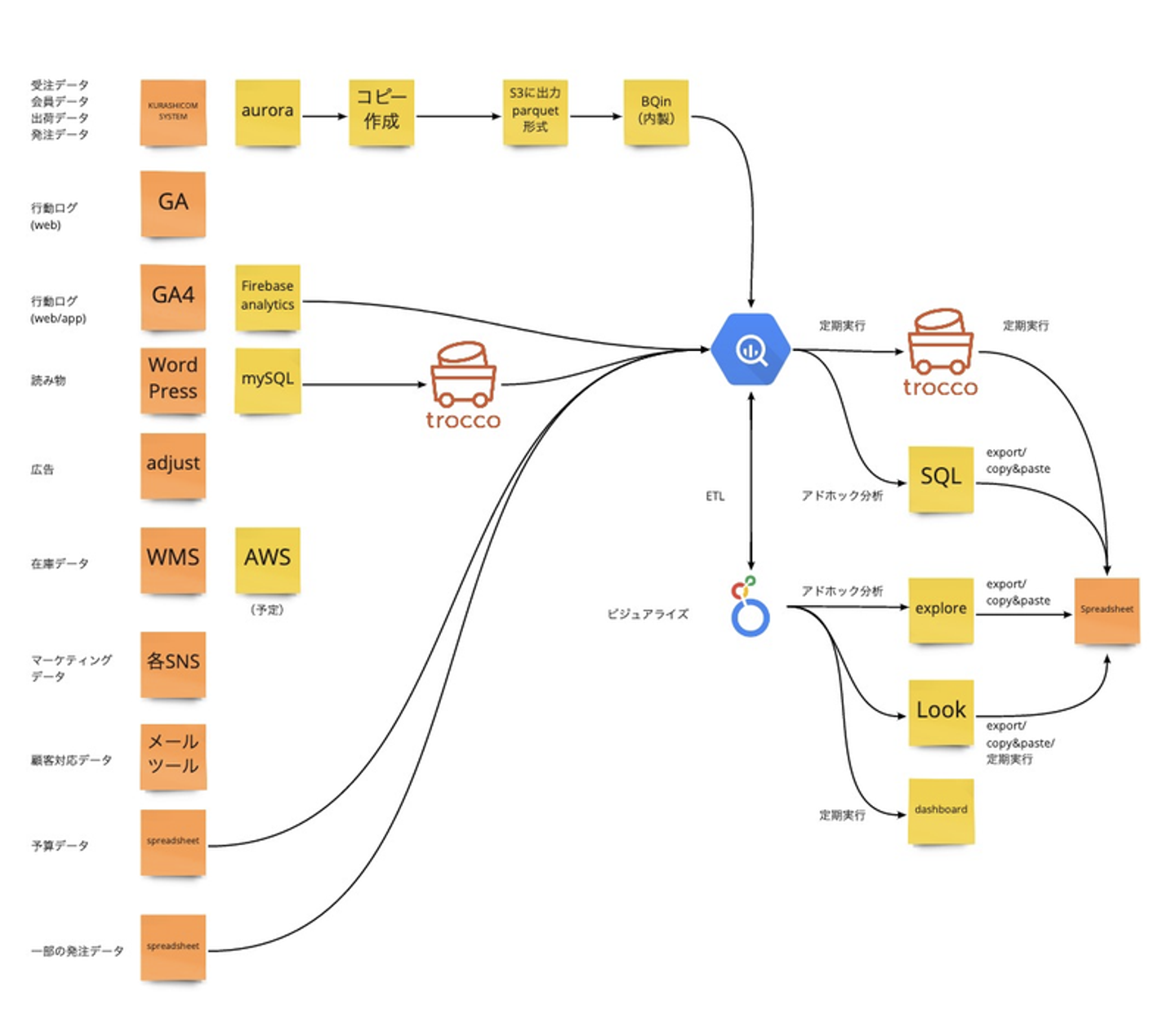
さらに、データ転送の効率化や、複数のデータベースをBigQueryに取り込むことによって、分析の対象を広げて、事業の状態を可視化したり、意思決定支援を加速させたい、という思いから、troccoを導入しました。
手始めに、読み物のデータが入っているWordPressのデータをBigQueryに接続したのはいいものの、それ以上のtroccoの活用に割く時間を取れていない期間が続いていました。そんな中、RedashのOSS版が2021年の11月いっぱいでサービスを終了する、というアナウンスがあり、一部のデータ転送でRedashの定期実行機能を使っていたQueryを救済する必要が生じたため、いま、troccoのデータ転送機能を用いて、鋭意Queryの移し替えを行っているところです。
今は、データマート生成のすべてをBigQuery-Looker間で実施しているのですが、これを、一部troccoに移すことで、エンジニアやLookMLを書ける人以外でもメンテナンスしやすい状態を作る、ということと、troccoの活用をさらに進めることによって、いまは分析対象にできていないデータにも、手を広げていきたい考えです。
最近導入したメールツール(Zendesk)からデータを取得することで、カスタマーサポートの生産性分析など、やってみたいです。
2年前くらいに「先生か一緒にもがいてくれる仲間かどちらかがほしい」という募集を出して、いい先生に恵まれたことで基盤構築が進んだ2年間でした。
今の業務委託の方々を中心とした体制は、とてもいい面があるものの今後のデータ分析チームのあり方としては、実はまだハッキリとした絵を描けていない状態です。
データアナリストにしろ、データエンジニアにしろ、人材を募集して、社内に専任の人がいた方がいいのか、あるいは、もう少しデータ分析チームの担う領域が広くなってから考えるべきなのか。
足場が固まってきた今だからこそ、チームをどうしていくべきかを考えていく楽しみも加わってきました。
今メインで募集しているのはエンジニアですが、データ分析にも興味があるよというエンジニアの方がいらっしゃったらぜひご連絡ください。

/assets/images/8987032/original/ddeeb212-469f-4efc-9ee4-c5b04a64e96d?1646380372)

![]()
/assets/images/8962265/original/c7866d47-17e7-4032-8d3d-04275630324d?1646121547)

